토토 경기 예측 자동 훈련 구조 설계 가이드
페이지 정보

본문

스포츠 베팅 시장은 수년간 수많은 통계와 전문가 분석에 의존해 왔습니다. 하지만 머신러닝 기술의 급격한 발전과 함께 예측 모델 역시 정밀하게 진화하고 있습니다. 단순히 과거 승률이나 팀 랭킹을 참고하던 방식에서 벗어나, 현재는 수천 건의 경기 데이터를 자동으로 수집·분석하며 실시간으로 예측 성능을 향상시키는 시스템이 주류를 이룹니다.
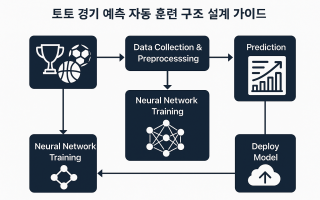
이러한 AI 기반 자동화 시스템의 중심에는 바로 토토 경기 예측 자동 훈련 구조 설계 가이드가 있습니다. 이 가이드는 데이터 수집부터 전처리, 특징 추출, 모델 학습, 평가, 그리고 자동 재학습까지 이어지는 전체 프로세스를 구조화하고 자동화함으로써, 더 높은 예측 정확도와 안정적인 모델 운영을 가능하게 만듭니다.
1. 왜 예측 모델 자동 훈련 구조가 필요한가?
토토 경기 예측 자동 훈련 구조 설계 가이드의 필요성은 명확합니다. 수작업으로 이루어지는 데이터 전처리와 예측 모델 재학습은 시간 소모가 크고, 실시간 베팅 환경에서는 치명적인 지연을 초래합니다.
AI 모델이 최신 경기 흐름을 반영하기 위해서는 지속적인 데이터 업데이트와 모델 재학습이 필수입니다. 자동화된 구조는 이러한 과정들을 완전히 시스템화하여 예측의 정확성과 반응 속도를 모두 만족시킵니다. 수작업 예측의 한계를 넘어서기 위해, 머신러닝 파이프라인의 전 단계를 자동화하는 것은 이제 선택이 아닌 필수입니다.
2. 전체 훈련 파이프라인 구조
토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다음과 같은 파이프라인을 기준으로 자동화 프로세스를 구축합니다. 각 단계는 독립적으로 설계되며, 스케줄러나 트리거 기반으로 순차적 실행이 가능해야 합니다.
css
복사
편집
[데이터 수집]
↓
[전처리 및 정규화]
↓
[특징 엔지니어링]
↓
[데이터 분할 및 모델 학습]
↓
[하이퍼파라미터 튜닝]
↓
[성능 평가 및 저장]
↓
[예측 결과 생성 → 시각화 대시보드 출력]
↓
[정기 재학습 → 성능 비교 및 자동 개선]
3. 데이터 수집 및 저장 구조
토토 예측 모델의 정확도는 데이터 품질에 좌우됩니다. 토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다양한 API 소스를 기반으로 다음과 같은 필드를 자동 수집하고 저장하도록 설계합니다.
필드명 설명
경기 ID 경기의 고유 식별자
경기 날짜 및 시간 시계열 분석, 시즌 구분용
리그 EPL, NBA, MLB 등
홈팀/원정팀 경기 분석의 기본 단위
배당률 홈/무/원정 각각 별도 저장
실제 결과 홈승(1), 무승부(0), 원정승(-1) 등 정규화
최근 성적 5경기 기준 승률, 득실차
포인트 차이 순위 및 팀간 실력 차이 반영 지표
데이터 소스는 SportsData.io, OddsPortal, FootyStats API 등 다양하며, 스케줄러 기반으로 주기적 수집이 가능합니다.
4. 데이터 전처리 자동화
전처리는 AI 예측의 기초입니다. 토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다음과 같은 전처리 단계를 자동화해야 합니다.
단계 처리 내용
결측치 보완 평균값 또는 중앙값으로 채움 또는 행 제거
범주형 인코딩 팀명, 리그명 → Label Encoding, One-hot Encoding 적용
이상치 제거 비정상 배당률 또는 무효 경기 제거
정규화 StandardScaler 또는 MinMaxScaler 적용
python
복사
편집
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['배당_홈', '배당_무', '배당_원정']] = scaler.fit_transform(df[['배당_홈', '배당_무', '배당_원정']])
5. 특징(Feature) 엔지니어링 자동화
정확한 예측을 위해서는 고도화된 특징 추출이 필수입니다. 토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다음과 같은 특징을 사용합니다.
특징명 설명
홈팀 최근 승률 최근 5경기 승률 기반
원정팀 평균 실점 수비력 평가용
경기 시간대 AM/PM/Night → 피로도 및 성능 차 반영
배당률 차이 신뢰도 분석 기반 지표
포인트/ELO 차이 팀간 전력차 분석 지표
6. 예측 모델 구성 및 학습
토토 경기 예측 자동 훈련 구조 설계 가이드에서는 예측 목적에 따라 모델을 선택합니다. 일반적으로는 RandomForest와 XGBoost가 많이 활용되며, 시계열 특성 반영 시에는 LSTM이 효과적입니다.
python
복사
편집
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X = df[features]
y = df['결과']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
7. 성능 평가 및 하이퍼파라미터 튜닝
예측 모델의 성능은 다양한 평가 지표로 측정됩니다. 토토 경기 예측 자동 훈련 구조 설계 가이드는 아래 지표를 기준으로 성능을 평가하며, 자동 튜닝 시스템과 연계됩니다.
지표명 설명
Accuracy 전체 예측 정확도
Precision 모델이 예측한 정답 중 실제 정답 비율
Recall 실제 정답 중 모델이 맞춘 비율
F1 Score Precision과 Recall의 조화 평균
ROC AUC 이진 분류 문제에서의 판별력
8. 예측 결과 저장 및 시각화
예측 결과는 분석뿐만 아니라 의사결정에 활용됩니다. 따라서 저장과 시각화는 필수입니다. Streamlit을 통해 실시간 리포트도 제공 가능합니다.
python
복사
편집
import streamlit as st
st.title("토토 예측 결과 리포트")
st.dataframe(predictions)
st.line_chart(score_history)
9. 자동 재학습 구조
토토 경기 예측 자동 훈련 구조 설계 가이드에서 핵심은 자동 재훈련입니다. 주기적으로 모델을 업데이트함으로써 최신 트렌드와 팀 변화를 반영할 수 있습니다.
항목 설명
스케줄러 사용 cron, Airflow, Prefect 등을 통해 자동화
재학습 주기 주간 / 경기 수 기준 설정 가능
모델 버전 관리 이전 모델 성능 대비 향상 여부 확인 후 적용
롤백 가능 성능 저하 시 기존 모델로 즉시 회귀 가능
10. 예측 피드백 루프 설계
예측 오류를 교정하고, 장기적으로 모델을 향상시키기 위해 피드백 루프가 필요합니다. 다음은 구성 요소입니다.
1. 실제 결과 vs 예측 결과 비교 및 로그 저장
모델이 생성한 예측값과 실제 경기 결과를 비교하는 과정은 예측 시스템의 정확도를 평가하고, 실패 사례를 분석하는 데 필수적인 작업입니다. 이 비교는 매 회차 단위로 실행되며, 다음 정보를 자동으로 로그에 저장합니다:
경기 ID, 날짜, 팀 구성
예측된 결과 vs 실제 결과
예측 확률(Confidence Score)
배당률 및 예측 기준 데이터
오차 발생 여부 (True Positive, False Positive, False Negative, True Negative 구분)
저장된 로그는 단순 통계 이상으로 활용되며, 모델의 취약한 조건이나 패턴을 찾아내는 기초 자료가 됩니다. 일정 기간 동안 누적된 비교 데이터를 기반으로 전체 예측 시스템의 신뢰도를 정량화할 수 있습니다.
2. 지속 실패한 경기 패턴 추출 및 특징 수정
단순한 예측 실패는 우연일 수 있지만, 반복적인 오예측은 구조적 결함의 신호입니다. 이 단계에서는 로그 데이터를 분석하여 다음과 같은 패턴을 자동 탐색합니다:
특정 리그 또는 경기 시간대에서 반복되는 실패
배당률 차가 작을수록 정확도 저하
특정 팀 간 경기에서 항상 잘못된 예측 발생
포인트 차이가 적은 경기일수록 예측 실패율 상승
이러한 패턴이 일정 기준 이상 누적되면, 해당 경기에 영향을 미치는 특징(feature)을 재검토하게 됩니다. 불필요한 특징은 제거하고, 새로운 특징을 추가하거나 기존 특징을 재구성하여 모델의 입력 데이터를 개선합니다.
3. 하이퍼파라미터 자동 재조정
모델의 성능은 학습 데이터만큼이나 하이퍼파라미터에 따라 크게 달라집니다. 예측 정확도 또는 F1 점수가 설정된 기준 이하로 하락하는 경우, 시스템은 자동으로 다음과 같은 파라미터를 재조정합니다:
n_estimators, max_depth (RandomForest, XGBoost 계열)
learning_rate, min_child_weight (Gradient Boosting 계열)
batch_size, dropout, hidden_units (딥러닝 계열)
재조정은 GridSearchCV, RandomSearch, Bayesian Optimization 등의 기법을 통해 수행되며, 성능 비교 후 최적 파라미터를 적용합니다. 이 과정을 자동화하면 인적 개입 없이도 지속적으로 성능 개선이 가능합니다.
4. 결과 기반 성능 향상 시 자동 버전 업데이트
모델 성능이 일정 기준 이상 향상된 경우, 시스템은 자동으로 모델 버전을 업데이트합니다. 이때 주요 과정은 다음과 같습니다:
현재 모델과 신규 모델의 성능 비교 (검증셋 기준)
신규 모델이 Accuracy, F1 Score, AUC 등에서 개선되었는지 확인
개선 시 기존 모델을 백업하고, 새로운 모델을 배포
기존 모델로의 롤백 옵션도 함께 유지 (재학습 실패 대비)
버전 업데이트는 모델뿐 아니라 해당 시점의 특징 구성, 전처리 방식, 하이퍼파라미터 설정값 등도 함께 저장하여 추후 회귀 분석에 활용될 수 있습니다. 이 버전 관리 시스템은 예측 시스템이 실시간 환경에서도 안정적으로 운영되도록 돕습니다.
FAQ
Q1. 어떤 데이터를 우선 수집해야 하나요?
A1. 경기 결과, 배당률, 팀 성적이 기본이며, 고급 정보로는 부상자, 피로도, 날씨 등이 있습니다.
Q2. 예측 정확도는 평균 얼마인가요?
A2. 보통 55~75% 수준이며, 데이터 품질과 리그 구조에 따라 달라집니다.
Q3. 모델 학습 주기는 어떻게 설정하나요?
A3. 주간 혹은 경기 수 기준 자동 설정 가능하며, 수동 트리거도 지원됩니다.
Q4. 실시간 배당 데이터 연동이 가능한가요?
A4. 네. Betradar, OddsAPI 등을 통해 실시간 연동이 가능합니다.
Q5. 시각화 도구는 무엇이 있나요?
A5. Streamlit, Dash, Tableau, Power BI 등 선택 가능합니다.
Q6. 딥러닝은 언제 도입하나요?
A6. 시계열, 연속성, 경기 흐름 분석이 중요한 경우 LSTM이 적합합니다.
Q7. 예측 오류가 반복될 경우 자동 수정되나요?
A7. 예. 재학습과 로그 분석을 통해 자동으로 개선됩니다.
Q8. 여러 리그를 동시에 분석할 수 있나요?
A8. 가능합니다. 리그 ID 또는 One-hot 인코딩으로 구분하여 적용할 수 있습니다.
토토 경기 예측 자동 훈련 구조 설계 가이드는 단순한 머신러닝 도입을 넘어서, 데이터 수집부터 결과 분석, 모델 업데이트까지 전 과정을 자동화하는 시스템 구축의 정석입니다.
모든 과정이 정밀하게 설계되어야 안정적인 예측 결과를 확보할 수 있으며, 이 가이드는 그런 자동화 구조를 실현하는 데 최적의 로드맵을 제공합니다. 토토 시장에서 차별화된 경쟁력을 확보하려면, 지금 이 순간부터 토토 경기 예측 자동 훈련 구조 설계 가이드를 실천하는 것이 가장 빠른 길입니다.
#토토예측모델 #스포츠AI훈련 #경기결과예측 #베팅AI시스템 #머신러닝토토 #스포츠데이터분석 #예측모델자동화 #토토자동학습 #스트림릿스포츠대시보드 #배당률기반예측
이러한 AI 기반 자동화 시스템의 중심에는 바로 토토 경기 예측 자동 훈련 구조 설계 가이드가 있습니다. 이 가이드는 데이터 수집부터 전처리, 특징 추출, 모델 학습, 평가, 그리고 자동 재학습까지 이어지는 전체 프로세스를 구조화하고 자동화함으로써, 더 높은 예측 정확도와 안정적인 모델 운영을 가능하게 만듭니다.
1. 왜 예측 모델 자동 훈련 구조가 필요한가?
토토 경기 예측 자동 훈련 구조 설계 가이드의 필요성은 명확합니다. 수작업으로 이루어지는 데이터 전처리와 예측 모델 재학습은 시간 소모가 크고, 실시간 베팅 환경에서는 치명적인 지연을 초래합니다.
AI 모델이 최신 경기 흐름을 반영하기 위해서는 지속적인 데이터 업데이트와 모델 재학습이 필수입니다. 자동화된 구조는 이러한 과정들을 완전히 시스템화하여 예측의 정확성과 반응 속도를 모두 만족시킵니다. 수작업 예측의 한계를 넘어서기 위해, 머신러닝 파이프라인의 전 단계를 자동화하는 것은 이제 선택이 아닌 필수입니다.
2. 전체 훈련 파이프라인 구조
토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다음과 같은 파이프라인을 기준으로 자동화 프로세스를 구축합니다. 각 단계는 독립적으로 설계되며, 스케줄러나 트리거 기반으로 순차적 실행이 가능해야 합니다.
css
복사
편집
[데이터 수집]
↓
[전처리 및 정규화]
↓
[특징 엔지니어링]
↓
[데이터 분할 및 모델 학습]
↓
[하이퍼파라미터 튜닝]
↓
[성능 평가 및 저장]
↓
[예측 결과 생성 → 시각화 대시보드 출력]
↓
[정기 재학습 → 성능 비교 및 자동 개선]
3. 데이터 수집 및 저장 구조
토토 예측 모델의 정확도는 데이터 품질에 좌우됩니다. 토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다양한 API 소스를 기반으로 다음과 같은 필드를 자동 수집하고 저장하도록 설계합니다.
필드명 설명
경기 ID 경기의 고유 식별자
경기 날짜 및 시간 시계열 분석, 시즌 구분용
리그 EPL, NBA, MLB 등
홈팀/원정팀 경기 분석의 기본 단위
배당률 홈/무/원정 각각 별도 저장
실제 결과 홈승(1), 무승부(0), 원정승(-1) 등 정규화
최근 성적 5경기 기준 승률, 득실차
포인트 차이 순위 및 팀간 실력 차이 반영 지표
데이터 소스는 SportsData.io, OddsPortal, FootyStats API 등 다양하며, 스케줄러 기반으로 주기적 수집이 가능합니다.
4. 데이터 전처리 자동화
전처리는 AI 예측의 기초입니다. 토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다음과 같은 전처리 단계를 자동화해야 합니다.
단계 처리 내용
결측치 보완 평균값 또는 중앙값으로 채움 또는 행 제거
범주형 인코딩 팀명, 리그명 → Label Encoding, One-hot Encoding 적용
이상치 제거 비정상 배당률 또는 무효 경기 제거
정규화 StandardScaler 또는 MinMaxScaler 적용
python
복사
편집
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['배당_홈', '배당_무', '배당_원정']] = scaler.fit_transform(df[['배당_홈', '배당_무', '배당_원정']])
5. 특징(Feature) 엔지니어링 자동화
정확한 예측을 위해서는 고도화된 특징 추출이 필수입니다. 토토 경기 예측 자동 훈련 구조 설계 가이드에서는 다음과 같은 특징을 사용합니다.
특징명 설명
홈팀 최근 승률 최근 5경기 승률 기반
원정팀 평균 실점 수비력 평가용
경기 시간대 AM/PM/Night → 피로도 및 성능 차 반영
배당률 차이 신뢰도 분석 기반 지표
포인트/ELO 차이 팀간 전력차 분석 지표
6. 예측 모델 구성 및 학습
토토 경기 예측 자동 훈련 구조 설계 가이드에서는 예측 목적에 따라 모델을 선택합니다. 일반적으로는 RandomForest와 XGBoost가 많이 활용되며, 시계열 특성 반영 시에는 LSTM이 효과적입니다.
python
복사
편집
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X = df[features]
y = df['결과']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
7. 성능 평가 및 하이퍼파라미터 튜닝
예측 모델의 성능은 다양한 평가 지표로 측정됩니다. 토토 경기 예측 자동 훈련 구조 설계 가이드는 아래 지표를 기준으로 성능을 평가하며, 자동 튜닝 시스템과 연계됩니다.
지표명 설명
Accuracy 전체 예측 정확도
Precision 모델이 예측한 정답 중 실제 정답 비율
Recall 실제 정답 중 모델이 맞춘 비율
F1 Score Precision과 Recall의 조화 평균
ROC AUC 이진 분류 문제에서의 판별력
8. 예측 결과 저장 및 시각화
예측 결과는 분석뿐만 아니라 의사결정에 활용됩니다. 따라서 저장과 시각화는 필수입니다. Streamlit을 통해 실시간 리포트도 제공 가능합니다.
python
복사
편집
import streamlit as st
st.title("토토 예측 결과 리포트")
st.dataframe(predictions)
st.line_chart(score_history)
9. 자동 재학습 구조
토토 경기 예측 자동 훈련 구조 설계 가이드에서 핵심은 자동 재훈련입니다. 주기적으로 모델을 업데이트함으로써 최신 트렌드와 팀 변화를 반영할 수 있습니다.
항목 설명
스케줄러 사용 cron, Airflow, Prefect 등을 통해 자동화
재학습 주기 주간 / 경기 수 기준 설정 가능
모델 버전 관리 이전 모델 성능 대비 향상 여부 확인 후 적용
롤백 가능 성능 저하 시 기존 모델로 즉시 회귀 가능
10. 예측 피드백 루프 설계
예측 오류를 교정하고, 장기적으로 모델을 향상시키기 위해 피드백 루프가 필요합니다. 다음은 구성 요소입니다.
1. 실제 결과 vs 예측 결과 비교 및 로그 저장
모델이 생성한 예측값과 실제 경기 결과를 비교하는 과정은 예측 시스템의 정확도를 평가하고, 실패 사례를 분석하는 데 필수적인 작업입니다. 이 비교는 매 회차 단위로 실행되며, 다음 정보를 자동으로 로그에 저장합니다:
경기 ID, 날짜, 팀 구성
예측된 결과 vs 실제 결과
예측 확률(Confidence Score)
배당률 및 예측 기준 데이터
오차 발생 여부 (True Positive, False Positive, False Negative, True Negative 구분)
저장된 로그는 단순 통계 이상으로 활용되며, 모델의 취약한 조건이나 패턴을 찾아내는 기초 자료가 됩니다. 일정 기간 동안 누적된 비교 데이터를 기반으로 전체 예측 시스템의 신뢰도를 정량화할 수 있습니다.
2. 지속 실패한 경기 패턴 추출 및 특징 수정
단순한 예측 실패는 우연일 수 있지만, 반복적인 오예측은 구조적 결함의 신호입니다. 이 단계에서는 로그 데이터를 분석하여 다음과 같은 패턴을 자동 탐색합니다:
특정 리그 또는 경기 시간대에서 반복되는 실패
배당률 차가 작을수록 정확도 저하
특정 팀 간 경기에서 항상 잘못된 예측 발생
포인트 차이가 적은 경기일수록 예측 실패율 상승
이러한 패턴이 일정 기준 이상 누적되면, 해당 경기에 영향을 미치는 특징(feature)을 재검토하게 됩니다. 불필요한 특징은 제거하고, 새로운 특징을 추가하거나 기존 특징을 재구성하여 모델의 입력 데이터를 개선합니다.
3. 하이퍼파라미터 자동 재조정
모델의 성능은 학습 데이터만큼이나 하이퍼파라미터에 따라 크게 달라집니다. 예측 정확도 또는 F1 점수가 설정된 기준 이하로 하락하는 경우, 시스템은 자동으로 다음과 같은 파라미터를 재조정합니다:
n_estimators, max_depth (RandomForest, XGBoost 계열)
learning_rate, min_child_weight (Gradient Boosting 계열)
batch_size, dropout, hidden_units (딥러닝 계열)
재조정은 GridSearchCV, RandomSearch, Bayesian Optimization 등의 기법을 통해 수행되며, 성능 비교 후 최적 파라미터를 적용합니다. 이 과정을 자동화하면 인적 개입 없이도 지속적으로 성능 개선이 가능합니다.
4. 결과 기반 성능 향상 시 자동 버전 업데이트
모델 성능이 일정 기준 이상 향상된 경우, 시스템은 자동으로 모델 버전을 업데이트합니다. 이때 주요 과정은 다음과 같습니다:
현재 모델과 신규 모델의 성능 비교 (검증셋 기준)
신규 모델이 Accuracy, F1 Score, AUC 등에서 개선되었는지 확인
개선 시 기존 모델을 백업하고, 새로운 모델을 배포
기존 모델로의 롤백 옵션도 함께 유지 (재학습 실패 대비)
버전 업데이트는 모델뿐 아니라 해당 시점의 특징 구성, 전처리 방식, 하이퍼파라미터 설정값 등도 함께 저장하여 추후 회귀 분석에 활용될 수 있습니다. 이 버전 관리 시스템은 예측 시스템이 실시간 환경에서도 안정적으로 운영되도록 돕습니다.
FAQ
Q1. 어떤 데이터를 우선 수집해야 하나요?
A1. 경기 결과, 배당률, 팀 성적이 기본이며, 고급 정보로는 부상자, 피로도, 날씨 등이 있습니다.
Q2. 예측 정확도는 평균 얼마인가요?
A2. 보통 55~75% 수준이며, 데이터 품질과 리그 구조에 따라 달라집니다.
Q3. 모델 학습 주기는 어떻게 설정하나요?
A3. 주간 혹은 경기 수 기준 자동 설정 가능하며, 수동 트리거도 지원됩니다.
Q4. 실시간 배당 데이터 연동이 가능한가요?
A4. 네. Betradar, OddsAPI 등을 통해 실시간 연동이 가능합니다.
Q5. 시각화 도구는 무엇이 있나요?
A5. Streamlit, Dash, Tableau, Power BI 등 선택 가능합니다.
Q6. 딥러닝은 언제 도입하나요?
A6. 시계열, 연속성, 경기 흐름 분석이 중요한 경우 LSTM이 적합합니다.
Q7. 예측 오류가 반복될 경우 자동 수정되나요?
A7. 예. 재학습과 로그 분석을 통해 자동으로 개선됩니다.
Q8. 여러 리그를 동시에 분석할 수 있나요?
A8. 가능합니다. 리그 ID 또는 One-hot 인코딩으로 구분하여 적용할 수 있습니다.
토토 경기 예측 자동 훈련 구조 설계 가이드는 단순한 머신러닝 도입을 넘어서, 데이터 수집부터 결과 분석, 모델 업데이트까지 전 과정을 자동화하는 시스템 구축의 정석입니다.
모든 과정이 정밀하게 설계되어야 안정적인 예측 결과를 확보할 수 있으며, 이 가이드는 그런 자동화 구조를 실현하는 데 최적의 로드맵을 제공합니다. 토토 시장에서 차별화된 경쟁력을 확보하려면, 지금 이 순간부터 토토 경기 예측 자동 훈련 구조 설계 가이드를 실천하는 것이 가장 빠른 길입니다.
#토토예측모델 #스포츠AI훈련 #경기결과예측 #베팅AI시스템 #머신러닝토토 #스포츠데이터분석 #예측모델자동화 #토토자동학습 #스트림릿스포츠대시보드 #배당률기반예측
- 다음글토토 베팅 조합기 성능 로그 관리 시스템 구축 가이드 25.06.19
댓글목록
등록된 댓글이 없습니다.